SBERT: How to Use Sentence Embeddings to Solve Real-World Problems
Ofcourse Transformers need no introduction (with the rise of ChatGPT i.e. Generative Pretrained Transformer for Chat). We have already read about Transformers & BERT in the text classification using BERT blog. In this one, we will learn about SentenceBERT or so called SBERT and also see how we can use it in our code.
What is SBERT?
SBERT is a framework for computing sentence embeddings using the BERT model which can be used for various downstream tasks but made computationally efficient with the use of Siamese Networks.
What is Siamese Network?
A Siamese Network is a type of network architecture that contains two or more identical subnetworks used to generate feature vectors for each input and compare them. Siamese Networks can be applied to different use cases, like detecting duplicates, finding anomalies, and face recognition. We provide three items to the model, where two of them will be similar (anchor and positive samples), and the third will be unrelated (a negative example.) Our goal is for the model to learn to estimate the similarity between items by minimising the distance between similar items and increasing the distance between dissimilar using something called Triplet loss function. Netflix utilises SNNs to generate user recommendations.

Triplet Loss — L(A, P, N) = max(‖f(A) — f(P)‖² — ‖f(A) — f(N)‖² + margin, 0)
where A is an anchor input, P is the positive input same as class A, N is a negative input from a different class from A, f is the embedding. It is based on the idea that the distance between the representation of the anchor and negative samples should be at least a “margin” distance more than the distance between the anchor and positive samples. Here, “margin” is a hyperparameter.
Why do we need SentenceBERT?
SBERT can be used in various usecases like Semantic textual similarity (STS), Semantic search, Text/Document Clustering, Natural language inference(NLI) etc. Some real-life use-cases are — Similar Product recommendations, Customer support, Personalized recommendations etc.
Okay but why not use normal BERT?
BERT is essentially a token embedder. So if we have to calculate similarity between 2 sentences using base BERT model — Two sentences are passed to the transformer network and the target value is predicted.

Finding the most similar pair in a collection of 10k sentences requires about 50 million inference computations (~65 hours) with BERT.
Another alternate solution is to take out the average of the word/token embeddings and calculate similarity score between just the embeddings. The results of this solution came out to be worse than averaging GloVe embeddings.
Okay then how does it solve the problem?
SBERT uses the BERT model puts it in something called siamese architecture and fine-tunes it on sentence pairs. We can think of this as having two identical BERTs in parallel that share the exact same network weights. SBERT adds a pooling operation to the output of BERT to derive a fixed sized sentence embedding (for e.g. 768 for bert-base by default). The default pooling strategy is MEAN
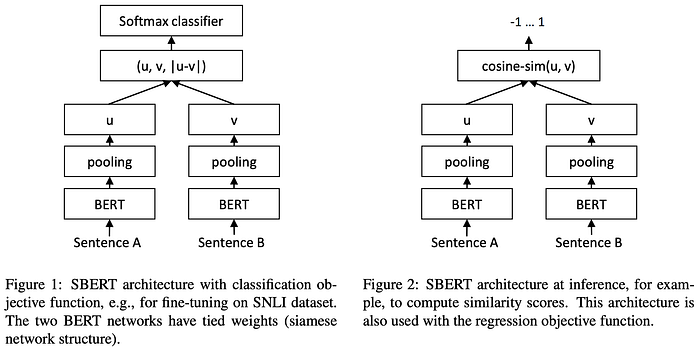
SBERT is fine-tuned with a 3-way softmax classifier [Figure 1] (labels being contradiction, eintailment, and neutral) objective function on the combination of the SNLI and the Multi-Genre NLI dataset (~1M sentence annotated pairs combined). MultiNLI covers a range of genres of spoken and written text. Training Params — batch-size = 16, optimizer = Adam, learning rate = 2e−5, linear learning rate warm-up = 10% of the training data.
SBERT outperformed previous methods of benchmarks like STS benchmark (STSb), Argument Facet Similarity (AFS) corpus and Wikipedia dataset from Dor et al.
Okay but how do I use it?
While inference we can use it to either
i) Get the sentence embedding of a given sentence to be used for some downstream task
ii) Get similarity score between 2 sentences using cosine similarity
#Install the library
! pip install -U sentence-transformers
#Import the library
from sentence_transformers import SentenceTransformer, util, InputExample, losses
#Load the model(here we use minilm)
model = SentenceTransformer('all-MiniLM-L6-v2')
#We get the embeddings by calling model.encode()
emb1 = model.encode("This is a red cat with a hat.")
emb2 = model.encode("Have you seen my red cat?")
#Get the cosine similarity score between sentences
cos_sim = util.cos_sim(emb1, emb2)
print("Cosine-Similarity:", cos_sim)Okay but how do I finetune it for my usecase?
There are various ways we can finetune it on our dataset to learn semantic similarity (using different ways of inputing dataset and loss function used). The most common 2 ways are CosineSimilarityLoss and TripletLoss (both of which are very similar — For learning through CosineSimilarityLoss we have to pass input data as pairs of sentences with a label between 0 and 1 indicating their similarity. For learning through Triplet loss we use 3 sentences 1 anchor sentence, 1 positive sentence — which is similar to anchor sentence and 1 negtaive sentences — which is dissimilar to anchor sentence).
#Using Cosine SimilarityLoss
from torch.utils.data import DataLoader
#Define your train examples. You need more than just two examples...
#Inputs are wrapped around InputExample class which the model expects
train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=0.8),
InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)]
#Create a PyTorch dataloader and the train loss
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
train_loss = losses.CosineSimilarityLoss(model)
#Tune the model
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100)We only change the format of the train examples and train_loss for training using Triplet loss.
#Using Triplet Loss
train_examples = [InputExample(texts=['My first sentence', 'My second sentence', 'Unrelated sentence']),
InputExample(texts=['My first sentence', 'My second sentence' 'Unrelated sentence'])]
train_loss = sentence_transformers.losses.TripletLoss(model=model)There is also something called Multiple Negative Ranking Loss which focuses on ranking multiple negative samples relative to a positive sample.
Hope this will help you learn about SBERT and put in to use in some real world probem for sentence similarity. Please do provide your feedback in form of responses and claps :)
References :
[1] https://arxiv.org/pdf/1908.10084.pdf
[2] https://www.pinecone.io/learn/series/nlp/sentence-embeddings/